U.S. footprint harmonization#
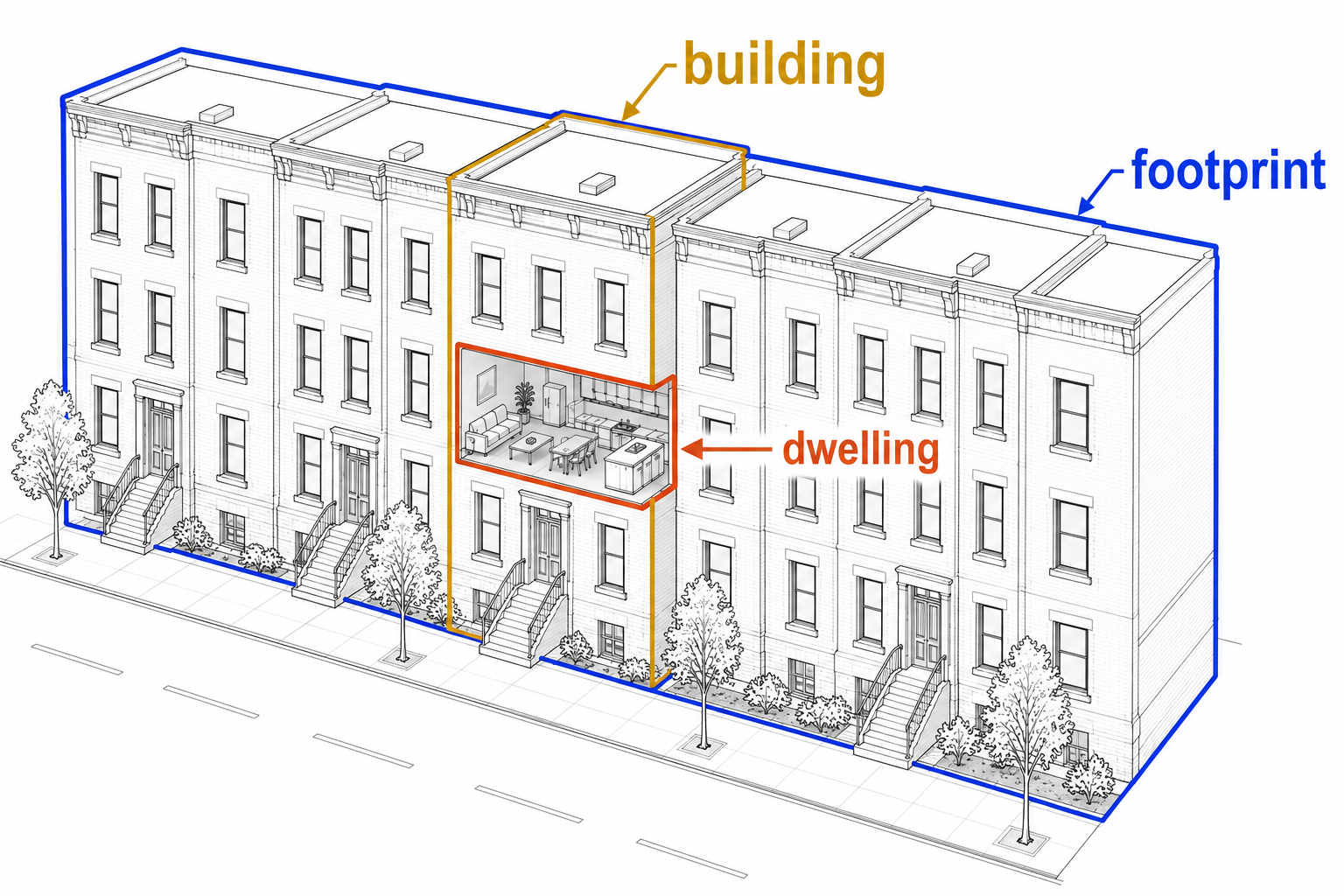
This recipe creates a footprint-level building inventory for U.S. hurricane damage and exposure modeling.
It resolves building footprints from multiple geometry sources (OpenBuildingsMap, Microsoft, local sources, FEMA), then enriches each footprint with data from linked parcels, the National Structure Inventory (NSI), and Overture dwellings (addresses).
This work is supported by NSF’s Coastal Hazards, Economic Prosperity & Resilience hub (CHEER). It is currently tested for use in Florida, Massachusetts, North Carolina, and Texas.
The companion notebook is:
notebooks/examples/US_harmonize_footprints.ipynb.
The recipe with instructions & thresholds is at:
src/openplaces/recipes/US/_all/footprint/cheer/2026/US_footprint-cheer-2026.yaml
What this recipe produces#
Running this recipe for a U.S. region will produce a building inventory at the footprint level for each county (level 3 in the administrative hierarchy) as a .parquet file.
Each row is a footprint, deduplicated across sources. If parcel information points towards the presence of another structure missing in any footprint dataset, the “footprint” geometry is the parcel boundary.
The table includes:
footprint_id, the unique ID of the footprint: its 11-digit openlocationcode).geometry: the footprint polygon, or a parcel polygon for inferred fallback records.source: the geometry source used for the row:obmfor OpenBuildingMap,microsoft,fema,nconemap.parcelflags parcel boundaries with unlocated buildings.footprint_role:primaryfor the primary footprint on a parcel,secondaryfor others,unknownif no parcel data was available.Parcel-derived attributes, including land value, improvement value, address, land-use or purpose classes, year built, and sometimes dwelling units.
NSI-derived attributes, including structure or occupancy class, structure value, number of stories, and block-median year built.
Overture-derived dwelling and address attributes, especially dwelling-unit point evidence and address components.
Reconciled final columns selected from competing source-specific columns.
Source datasets#
Source family |
Main contribution |
Common analytical use |
|---|---|---|
Footprints (detected) |
Building footprint geometries with associated data |
Exposure locations, structure area, hazard overlay, spatial joins |
Parcels (land ownership) |
Assessor values, land-use classes, addresses, year built, parcel context |
Valuation, land-use analysis, property-level aggregation |
National Structure Inventory (buildings) |
Structure-level point records with occupancy class, structure value, stories, and block-median year built |
Building-type classification, exposure modeling, crosswalks from parcel classes to structure classes |
Overture address points (dwellings) |
Residential unit and address point evidence |
Dwelling-unit estimation and primary-structure identification |
Footprints#
No single national dataset provides complete, high-quality building footprint coverage for the United States. Open datasets differ in geographic focus, detection method, and vintage: OBM has global scope but variable density; Microsoft’s ML-detected footprints give broad domestic coverage but are noisier in rural areas; state-specific sources often have the highest local accuracy but exist only for certain jurisdictions; FEMA USA Structures fills remaining gaps. The recipe therefore merges these sources rather than choosing one.
The spine is built by merging sources in priority order — OBM first, then Microsoft, then any state-specific footprint recipe found via auto_discover: true (for example, US-NC_footprint-nconemap-2024 in North Carolina), and finally FEMA as a fallback. Footprints smaller than 10 m² are dropped before merging.
Each source after the first is compared against the existing spine. A candidate footprint is added only if its intersection-over-union (IoU) with every current spine footprint is below 0.02. IoU is the ratio of intersection area to union area; a value above 0.02 means the two footprints share more than 2 % of their combined area and are treated as the same building.
Because IoU can miss displaced thin-rectangle footprints, the recipe also applies an elongated-footprint duplicate filter. Two footprints are treated as duplicates when they are both elongated (aspect ratio ≥ 2.5), their long axes are aligned within 15°, their long-axis projections overlap by at least 50 %, and their lateral separation is less than twice their average width. This catches parallel shifted representations of mobile homes and trailers that appear across two sources without enough polygon overlap to trigger the IoU threshold.
After merging, each spine row carries a geometry and a source column indicating which dataset contributed the footprint (e.g. 'obm', 'microsoft', 'nconemap', or 'fema').
Parcels#
Parcel datasets contribute assessed value, land-use classification, address, and year-built information. Depending on the jurisdiction this can include land value, improvement value, mailing address, land-use or property-purpose classes, year built, and dwelling-unit estimates. Coverage, field completeness, valuation conventions, and land-use code definitions are not uniform across counties or states.
Join method#
Parcels are polygons, so they are joined to footprints with a polygon identity overlay: each footprint is intersected with all parcels it touches, producing one row for every (footprint, parcel) pair. The crosswalk is a MultiIndex DataFrame indexed by (footprint_id, parcel_id) with columns area_intersection_m2, iou, and fraction_of_largest (this intersection’s area as a fraction of the largest intersection for the same footprint).
Two thresholds keep the crosswalk clean: links whose fraction_of_largest is below 1/6 are dropped (a footprint’s corner clipping a distant parcel should not be attributed), and intersections smaller than 10 m² are removed. After filtering, a footprint links to one parcel ('unique parcel'), multiple parcels ('multi-parcel footprint'), or none ('no parcel').
Some parcels with buildings on them have no footprint in any source — new structures and buildings under trees are common examples. The recipe adds a synthetic footprint for each such parcel that is likely to contain a structure, using two criteria that must both be met: the parcel’s purpose_group has a mean footprint count per parcel across the county of at least 0.2, and the parcel’s improvement_value_per_ha exceeds the 5th percentile of matched parcels in the same purpose group. Parcels that pass both tests receive a synthetic footprint whose geometry is the parcel polygon, tagged source = 'parcel.{source_id}'. After these inferred footprints are added, resolve_overlaps trims any geometry overlaps they introduce against existing OBM or Microsoft footprints.
Derived attributes#
All parcel columns are written with the suffix _parcel:
purpose_group_parcel,purpose_subgroup_parcel— direct from assessor land-use codes.openplaces_group_parcel— derived via a county-wide majority-vote lookup: for every footprint that has both a parcel link and an NSI link, the pair (purpose_group, openplaces_group_nsi) is recorded; the most common NSI group for each parcel purpose group is then applied to all footprints in the county via theirpurpose_group_parcelvalue. This propagates NSI’s structure-level occupancy vocabulary to parcels with no direct NSI match.improvement_value_parcel— split proportionally to intersection area. When any footprint on the parcel has dwelling-point evidence, area fractions for footprints without dwelling evidence are zeroed before the split, so improvement value accrues only to dwelling-linked footprints (Lochhead et al. 2026, Table 4).land_value_parcel— assigned from the largest-intersection parcel only; further restricted toprimaryfootprints to avoid assigning parcel land value to accessory structures.year_built_parcel— direct from assessor records.address_parcel— from the largest-intersection parcel.n_dwelling_units_parcel— area-weighted from the assessor unit count.overlap_fraction_parcel,n_other_footprints_parcel— diagnostic columns recording the footprint’s share of parcel area and the number of co-located footprints on the same parcel.
National Structure Inventory#
The National Structure Inventory contributes structure-level point records with occupancy class, structure replacement value, number of stories, and block-median year built. Unlike parcel records, NSI classifies individual structures rather than land-use parcels, making it a useful crosscheck on jurisdiction-specific assessor codes and a source of structure-type information for multi-structure parcels.
Join method#
NSI records are points; footprints are polygons. The four-pass proximity method (Lochhead et al. 2026, Table 3) handles imprecise geocoding:
Containment —
sjoin(predicate='within'). Points inside a footprint are matched directly.Inner proximity (10 m) — unmatched points within 10 m of a footprint edge (typical GPS error) are matched to the nearest footprint.
Outer proximity (100 m), same-parcel constraint — unmatched points within 100 m are matched to the nearest footprint on the same parcel. The parcel constraint prevents linking a point to a footprint across the street.
Unbounded fallback — disabled in this recipe.
When multiple passes produce candidate matches for the same point, the highest-quality match is retained.
Derived attributes#
All NSI columns are written with the suffix _building_nsi:
purpose_subgroup_building_nsi— NSI occupancy class (e.g.'Single Family','Multi-Family (2 units)').openplaces_group_building_nsi— mapped from occupancy class to the openplaces group vocabulary.structure_value_building_nsi— structure replacement value in USD.year_built_block_median_building_nsi— median year built for the census block, used as a fallback when parcel year built is absent.n_stories_building_nsi— number of stories.
Overture dwelling/address points#
Overture contributes geocoded residential unit and address evidence. Unlike NSI, which records one entry per structure, Overture records one point per residential unit: a ten-unit apartment building may have ten Overture points while NSI has one. Those points are used to count dwelling units and to help distinguish primary structures from accessory structures on multi-footprint parcels.
Join method#
The same three proximity passes as NSI are used (containment, inner 10 m, outer 50 m same-parcel). Two additional options are enabled for this join:
dedup_addresses: true— when a base address (street + house number) has both a building-level record and unit-specific records (e.g.Apt 1,Apt 2), the building-level record is dropped and each unit record is taggedn_dwelling_units = 1for downstream summation. This prevents double-counting units.aggregate_multipoint: true— multiple dwelling points matched to the same footprint are collapsed into one row withn_dwelling_unitssummed, giving the total residential unit count for that footprint.
Derived attributes#
All Overture columns are written with the suffix _dwelling_overture:
n_dwelling_units_overture— total attributed dwelling points (after deduplication and aggregation).address_street_dwelling_overture,address_number_dwelling_overture,postal_code_dwelling_overture,city_dwelling_overture— address components from the matched dwelling record.
Footprint role classification#
On parcels with more than one footprint (house, garage, shed, etc.), only the primary structure should receive the full parcel land value and, when dwelling evidence is absent for some footprints, the full improvement value. Each footprint is assigned one of three roles:
primary— the main structure on the parcel.secondary— an accessory structure.unknown— footprint not linked to any parcel.
The classification follows Lochhead et al. (2026, Table 4). Point evidence resolves ambiguity on multi-footprint parcels in this order:
If any footprint on the parcel has a linked Overture dwelling point, those footprints are
primary; the rest aresecondary.Otherwise, if any footprint has a linked NSI building point, those are
primary; the rest aresecondary.If no footprint on the parcel has any point evidence, all are
secondary— the recipe cannot determine which is the main structure.A footprint that is the sole footprint on its parcel is always
primary, regardless of point evidence.Footprints not linked to any parcel are
unknown, except those with dwelling-point evidence, which are promoted toprimary.
Dwelling evidence is evaluated before building evidence because Overture explicitly locates an occupied residential unit, whereas an NSI record may represent an accessory structure such as a detached garage.
footprint_role is stored as a pd.Categorical column on the spine.
Attribute reconciliation and design rationale#
Multiple sources provide overlapping information for the same footprint. After all source-suffixed columns are assembled, the recipe selects final values by filling from left to right across the suffixed columns in priority order:
Final column |
Priority order |
Rationale |
|---|---|---|
|
NSI before parcel |
NSI classifies individual structures; parcel codes describe land-use zoning and do not distinguish a house from its garage. |
|
Overture before parcel; occupancy fallback for remaining nulls |
Overture provides explicit counted units; parcel is an estimate. Remaining nulls are filled by a lookup table mapping NSI occupancy classes to expected unit counts (e.g. |
|
Parcel before NSI |
Tax-record year built is structure-specific; NSI provides only a block-median estimate. |
|
Parcel only |
No competing source provides an independent improvement value. |
|
Parcel only, restricted to primary footprints |
Assigning parcel land value to accessory structures inflates their apparent value; primary-only restriction avoids this. |
Source-suffixed columns (e.g. year_built_parcel, year_built_block_median_building_nsi) are retained in the output so users can inspect the evidence behind any final value and audit disagreements.
Several design choices underpin reliable reconciliation:
IoU deduplication rather than nearest-neighbor merging ensures that geometrically distinct nearby buildings — such as two row houses sharing a wall — are each retained as separate records rather than collapsed.
Elongated-footprint duplicate filtering catches displaced thin-rectangle footprints (mobile homes, trailers) that appear as parallel shifted rectangles across sources without enough polygon overlap to trigger the IoU threshold.
Area-weighted value distribution makes multi-parcel overlaps explicit and reproducible. When a single footprint spans two parcels, improvement value is distributed proportionally to intersection area, so allocations sum back to the full parcel total.
Dwelling evidence over building evidence when classifying primary structures prevents a detached garage (which may carry its own NSI record) from being misclassified as the main structure on a multi-footprint parcel.
Inferred parcel-shaped footprints preserve exposure and valuation evidence for structures absent from all footprint datasets, rather than silently dropping those parcels from the inventory.
Implementation walkthrough#
The recipe’s pipeline: list declares nine steps organized into four phases. Each step is a registered function that receives the shared HarmonizeState (carrying spine, references, crosswalks, and overlays), modifies it, and returns it.
Step |
Role in the recipe |
|---|---|
|
Builds the footprint spine from OBM, Microsoft, state-specific footprints, and FEMA, with IoU and elongated-footprint deduplication. |
Parcels |
Creates footprint-parcel overlay crosswalk and parcel-derived reference evidence. |
|
Adds inferred parcel-shaped footprint rows for likely missing structures. |
|
Trims overlaps introduced by inferred footprints. |
NSI |
Links NSI building points to footprints by four-pass proximity. |
Overture |
Links dwelling/address points, deduplicates address evidence, and aggregates multiple dwelling points per footprint. |
|
Derives |
|
Aggregates suffixed source columns and selects final values by source priority. |
|
Computes |
Running the recipe#
Activate the project environment before running development or data commands:
conda activate openplaces
The recommended entry point is the example notebook:
notebooks/examples/US_harmonize_footprints.ipynb
The equivalent script is available for batch or cluster execution:
scripts/examples/US_harmonize_footprints.py
The notebook and script cover ingestion of precursor datasets and the US_footprint-cheer-2026 harmonization recipe. Cached inputs and outputs are reused on subsequent runs unless reprocessing is requested.
Using the output#
Use geometry as the footprint polygon for spatial analysis, hazard overlay, and area calculations. For rows whose source indicates an inferred parcel source, the geometry is a parcel-shaped fallback and should not be interpreted as a precise building outline. Such rows are useful for exposure completeness but should be treated carefully in analyses that require roof shape, building dimensions, or parcel-independent geometry.
For most analyses, prefer final reconciled columns such as purpose_subgroup, n_dwelling_units, year_built, improvement_value, land_value, and derived area or value-per-area fields. These columns apply the recipe’s source-priority rules.
Parcel-derived columns reflect assessor data. Field completeness, valuation conventions, land-use code definitions, and year-built interpretation vary by jurisdiction and are not uniform across counties or states. Inspect source-suffixed columns when uncertainty matters: compare year_built_parcel against year_built_block_median_building_nsi, or purpose_subgroup_parcel against purpose_subgroup_building_nsi, to audit where sources agree or diverge. This is especially useful when analyzing valuation outliers, conflicting occupancy labels, or unexpectedly high dwelling-unit counts.
NSI and Overture are point-based sources. Their locations can be affected by geocoding imprecision, address ambiguity, or source coverage gaps. A missing NSI or Overture link for a footprint does not necessarily mean the structure has no occupants — it may reflect coverage or geocoding limitations rather than an absence of buildings or residents.
Interpret footprint_role as a derived analytical label:
primarymeans the footprint is treated as the main structure on its parcel, often supported by dwelling or building-point evidence.secondarymeans the footprint is treated as an accessory or non-primary structure on a parcel with another primary candidate.unknownmeans the recipe does not have enough parcel or point evidence to assign a primary/secondary role.
Final classes and values are harmonized estimates derived from multiple sources. They are not authoritative labels and should be validated before use in high-stakes parcel, valuation, or damage assessments.
Key reference#
Lochhead M, Zsarnoczay A, Deierlein G (2026) Exposure matters: a synthesis framework for high-resolution building inventory development. International Journal of Disaster Risk Reduction 139 (2026): 106148. doi:10.1016/j.ijdrr.2026.106148